Five PRIME Factors for EdTech Evaluation
As someone who has evaluated and published findings on an edtech program for two decades, closely watching the marketing hype in the math edtech market in particular, I’ve come to believe something you may find shocking: All edtech programs work.
That’s not as strong a claim as it may sound, because given the right sample size of the right mix of student types, the right implementation model, the right amount of usage, the right measurement tool (maybe even a test the edtech company itself created), the right comparison condition, and the right evaluator, any serious edtech program will generate positive outcomes—at least once. If you’re merely looking to check a box saying “It has evidence” before you commit to a program, you’re asking for something that can be generated by any program.
Savvy practitioners in the field of education should be dissatisfied with this simplistic “checkbox” approach to evaluating program effectiveness.
Merely checking whether an edtech product “works or not” fails to capture what the studies should also inform: nuances of different educational scenarios, different amounts of usage, and the range of outcomes for different learners. It is time to leave behind that old checkbox mentality and adopt a more comprehensive and useful lens through which to evaluate.
The focus must shift from dominantly spotlighting the wide range in formal rigor and confidence in the studies themselves (that “one good study” paradigm which I discussed here) to considering the range of credible facts that demonstrates a program’s effectiveness in real-world classroom settings. Having evaluated and published findings on MIND Education’s programs for over 20 years, I can distill the essential factors that should matter to practitioners. These factors are encapsulated in the acronym PRIME: Patterns & Repeatability, Implementation, Mix and Equity.
Patterns & Repeatability
Patterns & Repeatability are fundamental to establishing the reliability of any study finding. Conducting numerous comparable studies, standardized in their design and reporting, on an annual frequency enables the identification of consistent usage and impact patterns, and confirms that findings are replicable over time. These patterns provide crucial insights for practitioners, encompassing the effects of variations in usage such as amount, speed and regularity, and how that varies among different learners. Furthermore, frequent, comparable studies shed light on patterns of outcomes, including across grade levels, across different assessments, and for students at different performance levels. An annual frequency is vital due to the constant and significant changes over time to programs, standards or assessments, and the education ecosystem.
Implementation
Implementation goes beyond simply the initial assignment of the edtech product licenses. Yet you may be surprised to learn that “were assigned licenses” is the preferred usage yes/no metric for the treatment condition in gold standard edtech evaluations. In reality, implementation involves actual student usage of the program at various intensity levels. It’s not sufficient to evaluate an edtech program once or twice, at an unspecified and unanalyzed usage level, generating a thumbs up or down finding. In actuality, implementation varies tremendously. It is often spotty across schools or classrooms. A weak link that breaks usage is irregular attendance. It’s normal to have at least half of users not meeting the program’s usage targets. Evaluating and reporting these variations in usage, as well as their effects on group outcomes, is essential insight for practitioners. As noted above regarding patterns, but worth repeating: it is also crucial to explore implementation-related metrics and their interaction with student subgroups, such as completion rates and regularity of use.
Mix
The concept of Mix emphasizes the need for a high volume of studies sufficient to cover the nation’s diverse range of educational settings and program use cases. This goes beyond repeatability, which could be shown for just one district year after year. Evaluation of a wide mix of settings extends the validity of “one study” to each practitioners’ unique local conditions. For the necessary variety of mix, avoid sampling: study everyone, everywhere, while providing standardized reports which include breakouts for student groups (e.g., English learners, gifted & talented). The evaluation question can pivot from “was this program effective somewhere, sometime, in some way, with some demographic, at least once?” to “will this program be effective now, for my students, in my implementation model?” Note that quasi-experimental methods (see below) cover “non-experimental” use patterns by the students and teachers—their use is not colored by the knowledge that they are subjects of an experiment. Real-world use may be quite different from district-approved, highly planned and observed, and self-conscious experimental research use.
The size, number, frequency and recency of multiple large-scale quasi-experimental evaluations can outweigh a single, rare gold-standard edtech study.
Equity
Equity recognizes that not all students are the same, and indeed that different student subgroups may have distinct needs and experiences. We can not assume that each student assigned a program will generate some “average” type of use and impacts. It is crucial not to settle for a one-size checkbox approach that only reports out an overall “main effect” on “all” students.” Evaluating the program’s impact, and usage patterns, for each key student subgroup is necessary to even understand its effectiveness. The measured impact doesn’t need to be identical among subgroups, but it is essential to be aware of any disparities to address equity concerns.
Finding PRIME EdTech Evaluations
To achieve such a high volume of studies, the most feasible yet still rigorous approach is quasi-experimental group-comparison studies analyzed by school-grade level. This method, prescribed by the What Works Clearinghouse (WWC), also meets ESSA Tier II evidence standards. By evaluating entire school-grade cohorts using this method, universal state-level data available at grades 3-8 for math and reading can be leveraged. This nationwide dataset provides a substantial and longitudinal “control pool” for rigorous and closely matched comparisons to any set of user schools, starting at any time, including baseline matching based on school-level demographics. In fact, it’s possible to combine outcomes from various state assessments, increasing the study sample size and allowing for national analyses—including even data from states with low numbers of schools using the program.
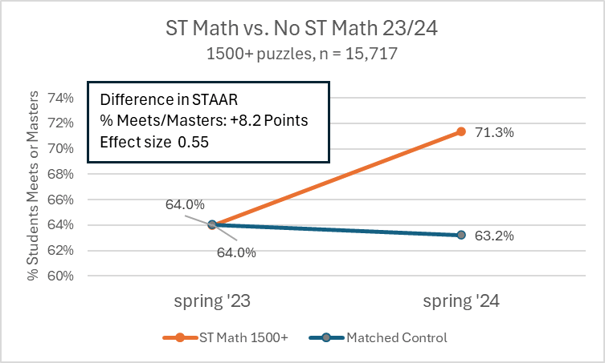
MIND Research Institute has collaborated with WestEd to validate these rigorous quasi-experimental methods, which have been implemented every year since 2008 to evaluate every new school cohort using the ST Math program. This quasi-experimental WestEd study is verified by SRI to meet What Works Clearinghouse (WWC) quality evidence standards.
The quasi-experimental studies conducted by WestEd show a correlation between high-fidelity usage of ST Math and growth on state assessments – evaluating all user schools in all districts, across different states using different high-stakes tests. Learn more here.
In summary, by focusing on the key elements of PRIME, administrators can make vastly better-informed decisions regarding the adoption and implementation of educational technology programs. There is no need to become an expert in navigating academic research papers. Instead, practitioners can use the PRIME framework as a guide to request specific types of information from program providers or researchers. This knowledge empowers administrators to assess how complete the evidence is, determine the program’s requirements and best applications, and even identify the potential risks. PRIME info enables them to determine how well a program will align with their specific needs and the likelihood of their own sites achieving the necessary use for results.
Key Takeaways for Educators
When making well-informed decisions about edtech programs for your school or district, it’s crucial to look beyond merely checking a go/no-go box. Here are some of the questions to ask:
- Patterns & Repeatability: How frequent and recent are the studies?
- Implementation: How much usage is required for the desired level of impact?
- Mix: How closely do the studies match situations like mine?
- Equity: Are the results equitable across different student subgroups?
Shifting from a simplistic checkbox approach to a comprehensive evaluation suite of information will greatly empower program evaluation and selection. By embracing PRIME, edtech evaluators, program providers, and educators can each move beyond the limitations of a narrow “works or not” mindset and gain deeper insights into program effectiveness, implementation strategies, and equity considerations in real-world contexts—for their real-world students.